
If a machine learning model was a chef…
A fun analogy taken to an extreme (and a test for ChatGPT)

One of the things I most enjoy is taking a complicated concept and making it intuitive through the power of analogies. So, for fun I set myself the challenge to come up with a wide-ranging culinary analogy to describe the various key components of machine learning that underpin modern AI.
To speed things up, I also thought it would be an interesting test of collaboration with ChatGPT, given it excels in drawing and making up connections between obscure topics, which is a key part of constructing analogies.

Here’s what “we” came up with, in summary:
Imagine the machine learning model is a master chef.
Training the model is like the chef's apprenticeship and ongoing practice. A model learns patterns and relationships within the data, much like how a chef learns to combine flavours and ingredients.
Data represents the raw ingredients.
Data is needed both to train the model (chef) originally, as well as serve as inputs from which outputs (meals) are produced when the finished model is in use.
The algorithm is akin to the chef's repertoire of cooking techniques and recipes.
The algorithm reflects a chef’s knowledge of how different ingredients (data points) can combine to create a variety of dishes (predictions or outputs). Different algorithms are like different cooking styles – some are better suited for certain tasks than others.
The computing environment - the hardware, software, model architecture - is like a kitchen.
Just as a kitchen must be well-equipped with the right tools, space, and layout for efficient cooking, the computing environment must have the necessary computational power, storage, software and architecture to efficiently process data and execute algorithms.
Putting all this together to build an AI system is like opening a restaurant.
Opening a restaurant parallels launching an AI system, where choices about deployment environment and design dictate who will be your customers. Success in both hinges on a skilled team, high-quality resources, and the ability to evolve and refine continuously to meet changing needs and preferences.
So far so good. But the real test of a good analogy, and where it gets interesting, is when you drill into the details. So I pushed it further, and while it gets a little belaboured in parts, fortuitously the analogy does seem to still hold together! As a bonus extra I decided to illustrate it with retro cooking pictures, because with artist-extraordinaire ChatGPT by my side WHY NOT. 😊
Appendix: A glimpse behind the scenes on how I wrote this note
I hope this gives you a flavour (sorry bad pun) of how AI works, through a fresh lens - as well as a practical illustration of how tools like ChatGPT might be harnessed for content-generation tasks. Comments and questions welcome :)
1. Model ⇒ master chef
Imagine the machine learning model is a master chef. Training the model is like the chef's apprenticeship and ongoing practice. A model learns patterns and relationships within the data, much like how a chef learns to combine flavours and ingredients.
A machine learning model, like a master chef, uses various algorithms (recipes and techniques) to process and understand data (ingredients). Like a chef refining their skills through trial and error, a machine learning model improves by analysing data, making predictions, and adjusting based on its accuracy. Fine-tuning a model involves making small adjustments to a pre-trained model so it performs better on a specific task or dataset, much like a chef tweaking a recipe to get that perfect flavour balance for a particular palate.

Models, like chefs, take many forms.
Some are general purpose – they are skilled enough to handle anything you throw at them. Others are more specialist – they may be the world’s greatest sourdough baker but terrible at omelettes.
Different chefs, like different models, will be trained to suit different cultural contexts in the aspects they emphasise and the trade-offs they make in crafting their outputs.
Scale matters. Some chefs are able to command large kitchens to deliver banquets; others are better suited to a pop-up supper-club – just as some models need data centres to run on and others can work on your phone.
There is variance in the level of robustness and reliability. Some chefs (and models) will be occasionally genius but also occasionally dire, depending on your luck on the day. Others will be steadier and while they may not reach the same serendipitous heights of quality, will be a model - or chef - you can trust to always reach a certain standard.
But a key thing that is often overlooked about models is that, like superstar chefs, sometimes their era is over. It might be that the world has changed – different tastes have emerged, or different patterns of behaviour mean that the data the model was trained on is no longer representative. Or it might simply be that a once cutting-edge approach has been superseded by something better. The exciting thing is that new kinds of models are emerging all the time. There has never been a better time to be culinarily or computationally adventurous!
2. Data ⇒ raw ingredients
Data is needed both to train the model (chef) originally, as well as serve as inputs from which outputs (meals) are produced when the finished model is in use.
Data, like raw ingredients, can have different provenances and characteristics that are important considerations in determining their quality and usefulness.
Some ingredients may have arrived very overtly (“look at this amazing whole salmon I found at the market!”, akin to someone proactively filling in a survey to share their information with you). Others may have arrived via back-door methods, akin to a poacher’s drop-off or via surreptitiously scraping web data.
Many ingredients may be fresh, having arrived via the latest supermarket shop, akin to data generated by recent usage of your products. But there are also likely to be ingredients in your pantry that are old and no longer as flavourful or useful. A bag of sea salt with rosemary bought in Greece a decade ago is like decade-old information about a person’s interests — both are long past their prime.
Some ingredients may be fully natural (like a dried vanilla pod, or directly observed data), while others are ultra-processed fakes (like aspartame or synthetically generated data).
For every ingredient, there is a judgement call to make about how safe it is to use. Using ingredients of unknown provenance is always a bit of a gamble, and even more so if your diners have allergies. Some items past their use-by might still be safe and just have lost some flavour if they’ve been stored carelessly, whereas others could kill you if they’ve not been kept in the right conditions or prepared in the right way. It’s a similar story for training data. It’s not just about having relevant data on hand for the problem you’re trying to solve (akin to relevant ingredients for the dish you want to make); it’s also about the data, in aggregate, being of a suitable quality, volume, breadth and provenance, and prepared in the right way.

Data needs to be relevant and representative
If you are wanting to make three different dishes, it’s no good if you only have the ingredients for two of them; or if you have the ingredients but not in the right quantities. The same is true for datasets.
Example: Imagine you were making an AI model to detect faces in images. If you want your face recognition system to perform similarly well for all types of people, the training dataset will need to contain images of people with differing ages, skin tones, hairstyles, levels of accessorisation, and so on. Similarly, if you want your face recognition system to be as accurate on imagery from a crowded street or restaurant with dim lighting, as in a well lit photo booth, then your training dataset needs to contain data from the relevant contexts for the same broad mix of people. Data can be synthetic
Sometimes you may not be able to get enough ‘real’ data. It might be too costly or tedious to acquire; it might be blockaded from access by copyright or competition barriers; or it may simply not exist (like with rare diseases). In such scenarios, an alternative can be to create artificial data, just like sometimes cooks need to work with substitute ingredients due to allergies or supply disruption. Sometimes synthetic data could be rooted in real data (e.g., taking a real image like a scan of a tumour, and rotating it, or cropping it in different ways, to create multiple different images). Other times it could be artificially generated such as via an AI image generator that creates a library of realistic looking faces that are not based on a real person. Improving ways to generate useful synthetic data is an ongoing area of research.
Data needs to be cleaned up and pre-processed
Before cooking, chefs prep their ingredients – washing, peeling, cutting up, marinating, etc – to get them into the format that is most suitable for what they are trying to produce. There is a similar need to prepare and curate the data you possess so it is best suited to the task at hand. Sometimes the rationale for pre-processing is safety (e.g., cutting the leaves off fresh picked rhubarb as they’re deadly poisonous – akin to the efforts made to filter out images of graphic violence from a dataset if you never want such imagery to be recognisable or produced by the AI system). Sometimes though it’s just a question of taste (e.g., opting to peel potatoes that are to be mashed, even though mashing potatoes with the skins left on is perfectly edible and might even be healthier - is akin to deciding to assign labels to data, or segregate it into clusters, rather than just leaving it to serendipity in a single pile).
Datasets should be ethically and legally sourced
Just as people increasingly care about the provenance of food (is it organic? was it sourced ethically?), so too are there questions of data provenance. Where did the data come from? Was it generated as a byproduct of people using your products, and if so are they aware of this, and did they consent? Was it scraped from the Internet, and if so was this legal to do and is it representative? Is anyone likely to freak out - either for copyright or privacy reasons - about you having this data and using it for training an AI model?
Unfortunately this is an aspect that not everyone will put the same value on, since it so often imposes trade-offs in cost or availability. There will always be those who opt to take their chances and turn a blind eye to data ethics and legality – just as there will always be a black market trade in stolen and bartered goods. The ethics of using data are not always as black and white though, as sometimes people might genuinely believe that the use of data is warranted under ‘fair use’ or for the greater good.
For example, some datasets used to train face recognition models were derived from scraping creative commons imagery published on Flickr. Some people got upset by this as it wasn’t something they'd envisaged, even though they'd explicitly allowed their imagery to be used for any purpose under the terms of the creative commons license. Others may more legitimately be upset, such as if they appeared in creative commons photos published by their friends who did not seek their consent. 3. Algorithms ⇒ recipes and cooking techniques
The algorithm is akin to the chef's repertoire of cooking techniques and recipes. It reflects a chef’s knowledge of how different ingredients (data points) can combine to create a variety of dishes (predictions or outputs). Different algorithms are like different cooking styles – some are better suited for certain tasks than others.
Algorithms represent different approaches to “cooking” with data, showcasing how diverse techniques and strategies can be applied to achieve various goals. In practice, the distinction between choosing a model architecture and an algorithm often blurs, especially in deep learning, where the architecture itself is crucial to the model's ability to learn from data.
In the same way that different cooking techniques are suited to different types of dishes, the choice of algorithm is heavily influenced by the problem at hand, including the objectives you are trying to achieve and the nature of the data. A key consideration is the performance trade-off, which involves balancing accuracy against computational efficiency both in training and in the cost and time required to generate an output. Algorithms also vary in their interpretability, so if you need to be able to explain a model’s output in detail it will constrain your algorithm choices. (Of course, with enough effort and pre-planning you can usually get a partial explanation of the output for any kind of model, but this is seldom practical as a matter of routine).
Just as chefs experiment with new recipes, programmers often try different algorithms, tweaking and tuning them to see which yields the best results. Some of the biggest modern day breakthroughs in machine learning have come from algorithmic advances paired with new architectures (e.g., attention mechanism in transformers, back propagation in neural networks)
Examples of algorithms







4. Computing environment ⇒ kitchen
The computing environment - the hardware, software, architecture - is like a kitchen. Just as a kitchen must be well-equipped with the right tools, space and layout for efficient cooking, the computing environment must have the necessary computational power, storage, software and architecture to efficiently process data and execute algorithms.
Different ovens have varying capabilities, efficiencies, and specialities, much like how different hardware (like CPUs, GPUs, or TPUs) have their strengths and weaknesses. Some ovens might be better for baking; others might be better for grilling, analogous to how different kinds of computational tasks are more efficient when using particular kinds of hardware and chips. This is why chip design has become such a big deal in recent years - people are designing chips now that are optimised for running particular kinds of algorithms.
The various utensils, pots, pans, and gadgets in the kitchen can be likened to the software tools and libraries used in machine learning (e.g., TensorFlow, PyTorch, or scikit-learn). Each tool has a specific function - a blender mixes ingredients smoothly, just as a data visualisation library like Matplotlib helps in understanding data trends. Choosing the right tool for the right task is crucial in both cooking and machine learning for efficient and effective results.

The overall setup and organisation of the kitchen, including how utensils and ingredients are arranged, represents the model architecture and workflow in machine learning. A well-planned kitchen layout allows for efficient movement and workflow, ensuring that dishes are prepared and served promptly – so too an efficient model architecture ensures that data is processed effectively, and predictions are made quickly and accurately.
Think of layers in a neural network as being like the parts of a kitchen dedicated to chopping and preparing ingredients, adept at handling specific types of data (like images). Just as larger kitchens with more stations can prepare more complex and varied dishes, a more complex model architecture (with more layers and neurons) can handle more complex tasks and data. But it will often also come with the trade-off of being harder to explain and more computationally intensive.
Sometimes the nature of the application will limit your choices of model architecture. For example in contexts like chatbots where a real-time response is required, you need architectures that balance performance with computational efficiency. This is similar to cooking in a fast-paced restaurant where dishes must be prepared quickly, and so creative workarounds like partial pre-cooking are necessary. Other contexts may require such a high degree of explainability that the most complicated (and hard to understand) models are simply nonviable (e.g., if regulations require that you be able to give a detailed rationale for individual decisions).
How much flexibility is desired also affects design choices for both kitchens and model architecture. For example, a factory kitchen designed solely to produce jam on an industrial scale will differ dramatically from a kitchen in a cooking school that needs to be able to churn out small quantities of any dish at a moment’s notice. Similarly, some model architectures are more flexible than others, able to handle a variety of tasks and be adapted to new problems easily, whereas other architectures may be precisely tailored to carrying out one type of task. Just as in the culinary world, the choice of model architecture in machine learning depends on the task at hand and the level of flexibility or specialisation required.
Examples of model architectures







5. Building an AI system ⇒ Designing a restaurant
Opening a restaurant parallels launching an AI system, where choices in environment and design dictate clientele and user base, respectively. Success in both hinges on a skilled team, high-quality resources, and the ability to evolve and refine continuously to meet changing needs and preferences.
Launching a restaurant is like designing and deploying an AI system. Much like how a restaurant's location, dining ambience and pricing dictate its clientele, the deployment environment (like web, mobile, or enterprise systems), functionality and user interface, and cost of access will determine who is likely to use an AI system, and in what manner. Similarly, in the same way that a successful restaurant must evolve in tune with its customers' changing tastes, an effective AI system must be monitored and refined over time to stay relevant and useful.
Just as no restaurant can offer Michelin-quality cuisine without a stellar crew, top-notch ingredients, and a well-appointed kitchen, the performance of an AI system is bounded by the expertise of those assembling it and the resources at their disposal. The most successful AI applications are underpinned by a magical blend of skilled people, data, and technology, coming together at the right time and place, like the culinary alchemy when a restaurant gets all the elements right.
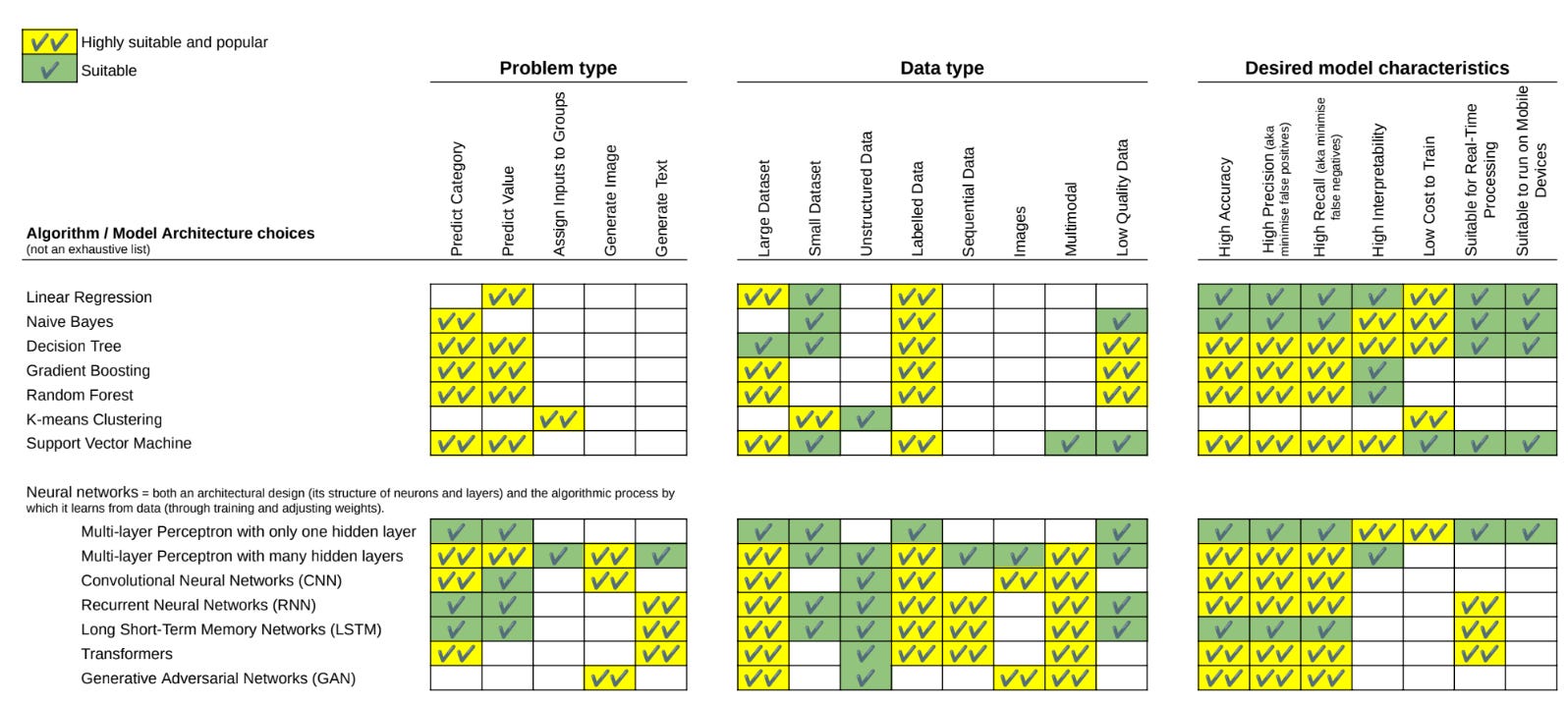
Each component of an AI system, like a culinary dish, demands a unique blend of 'ingredients' – data, algorithms, model architectures – prepared in a suitable 'kitchen,' the computing environment. Balancing many different factors to decide on an optimal approach is part of the art of AI system design. The following table attempts to give a flavour of some of the key considerations that go into making these design choices. Caveat: this list of algorithms is far from exhaustive, and their mapping vs problem/data type and desired model characteristics is unlikely to be 100% accurate, partly because I’m not an ML engineer, but also because the state of the art changes all the time. If you spot anything that looks wrong, let me know and I’ll update. For now though, I share this working draft to illustrate the kind of trade-offs that go into making an AI system. :)
Appendix: A glimpse behind the scenes on how I wrote this note
Writing this note was done in close collaboration with ChatGPT, as part of my hands-on exploration of how helpful it can be in day-to-day work. While I provided the spark in terms of motivation and many nudges in the form of (educated) questions during the conversation, all of the imagery and much of the legwork of wordsmithing of first drafts was down to ChatGPT.
In terms of process, the image generation was more ‘centaur’ style as described in this research:
“Centaur work has a clear line between person and machine, like the clear line between the human torso and horse body of the mythical centaur. Centaurs have a strategic division of labor, switching between AI and human tasks, allocating responsibilities based on the strengths and capabilities of each entity”.
In this case, my artistic execution skills are near non-existent, but I am very much a fan of old school cook book imagery. So I pasted in a few of the text paras and gave ChatGPT the guidance: “Can you create a series of images to illustrate these cooking analogies? Please make it in a retro 1950-60s era styling and colours, like what you might have found in Life magazine profile of a chef or restaurant”, and then away it went. Amazingly, most of the images are what it came up with on a first pass.
The writing however, was much more cyborg in approach:
“Cyborgs blend machine and person, integrating the two deeply. Cyborgs don't just delegate tasks; they intertwine their efforts with AI… Bits of tasks get handed to the AI, such as initiating a sentence for the AI to complete, so that Cyborgs find themselves working in tandem with the AI”
I asked ChatGPT leading questions in a conversational to and fro fashion. For example:
“In this analogy, what is the kitchen? What would the choice of oven brand and kitchen equipment represent?”
“You said earlier that we should imagine the kitchen as the computing environment, with the ovens and pots and pans representing hardware/software libraries; and a model in machine learning as a master chef. In this analogy, how would you describe the model architecture?”
“Could you give me some concrete examples of model architectures that are more flexible, as well as some that are more tailored to do just one thing?”
I copy-pasted snippets of ChatGPT’s text as a bouncing off point - sometimes just editing and playing with words to make it more punchy; other times rewriting multiple paragraphs from scratch inspired by a thought the conversation had sparked. And in a few instances, I left it as verbatim. When there was confusion I asked for clarification, and of course double-checked when it mentioned something I was not familiar with to make sure it wasn’t just making it up! I also was a very fussy client, showing no compunction about asking to ‘try again’ with guidance to highlight or downplay a particular element, or avoid a certain phrasing.
Overall, this post still took me several days of work to craft, and so I have no qualms about claiming authorship as I’ve put in the legwork. But the end result is more thorough than it would have otherwise been - and the writing process was much more enjoyable. (In fact I doubt I’d have even attempted it without ChatGPT’s help as it would have been too tedious and not worth the time taken).
Inspiring as usual, Lynette. A question for your future musings: how do you see AI influencing the evolution of interface?
So far we've been living in an app world. But new comers like Rabbit R1 come with a device designed for the their AI system. It's clearly just a first iteration, but it makes sense to foresee an evolution of connected devices, not just systems. What do you think?