


My thoughts on AI safety
A four-part overview for anyone new to the AI safety debate, and why I'm more worried than two years ago - but also still cautiously optimistic.


When I first started working on AI policy at Google, I was surprised how tetchy the researchers I was working with got about using the term ‘AI safety’. To me it was a commonsense phrase that captured the essence of the goal — to make sure AI systems were not harmful to those who used them. The problem, it turned out, was that in research circles ‘AI safety’ had come to be shorthand for talking about longer-term sci-fi-esque fears over whether humanity could retain control of superintelligent AI and whether misaligned systems might turn us all into paperclips. Given the limitations of AI’s performance at the time (6+ years ago), superintelligent AI seemed a very distant prospect — and thus discussion of AI-related existential risk was seen by many as an unhelpful distraction from tackling critical problems of the here-and-now, namely improving AI fairness, accountability and transparency (FAT-ML).
But then in the past year, ChatGPT blew everyone’s expectations out of the water. As Bill Gates put it
“I knew I had just seen the most important advance in technology since the graphical user interface”.
OpenAI spearheaded a massive industry wave of Generative AI development, with ever-more impressive performance, and suddenly super-smart AI — and the safety risks it may pose — didn’t seem so far-fetched. Cue various open letters signed by the AI literati — “Pause giant AI experiments”, “Mitigating the risk of extinction from AI should be a global priority” — and even a TIME article suggesting that we should “shut it all down”.
It’s safe to say that governments got the message! On October 30th, President Biden issued an Executive Order on Safe, Secure, and Trustworthy AI, which in its breadth and depth leapfrogs the US from laggard to top table in AI-related regulation, including around safety. Not coincidentally, the day after the UK staged their AI Safety Summit, pulling off the diplomatic coup of getting 28 countries including the US, Europe AND China to sign the Bletchley Declaration, and kickstarting what seems to be genuine momentum towards developing international governance mechanisms to address AI safety concerns.
AI safety is not a topic I’ve written about before, so seems apt fodder for my first essay. I’m writing this as a forcing device for me to get my own thoughts in order — but I also hope it will help demystify things for anyone new to the topic.
This note is divided into sections, so feel free to skip ahead.
To begin, a look at why people are scared — setting the scene with context on the state of AI development today, followed by a quick jaunt through the key worries. In a nutshell, the concern is driven by a combination of the surprising pace of advance, the cold-shower reality that we still understand so little about how AI works, and sci-fi-esque nightmare fears about what might go wrong.
Next, a quick rundown on what’s being done to tackle AI safety risks by industry and by governments. In particular, focusing on some key recent initiatives aimed at tackling AI safety risks for the most cutting edge foundation models.
To finish, my personal take on the question of how worried to be. Spoiler: I’m much more worried than I was two years ago, but still cautiously optimistic.
1. Three things you should know about the state of AI today
To fully grasp the reasons for people’s fears, you need a little context on the state of AI development. We are in the unusual situation where AI capabilities are leaping far ahead of our understanding, and it shows no sign of abating.
» It’s not unreasonable to assume rapid, unforeseen leaps in performance
AI is not new, but over the past few years it’s suddenly become VERY useful, VERY fast. As just one illustration, consider the advancement in the prowess of large language models (LLMs), which underpin the latest wave of generative AI. For the identical prompt, compare the sophistication and usefulness of the following responses:
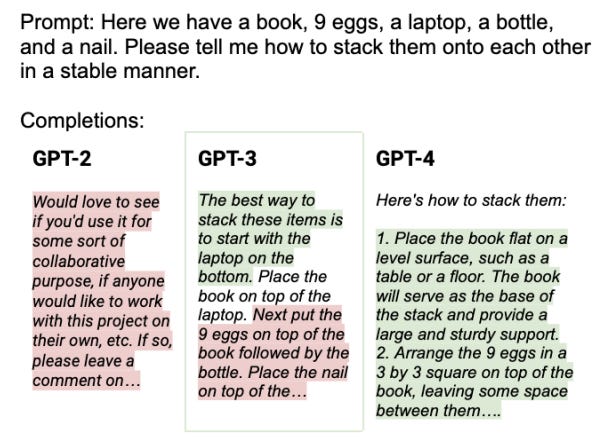
It’s fair to say that this pace of LLM advance was unexpected, even to those developing it. As Ilya Sutskever (Chief Scientist at OpenAI) later admitted:
“when you asked it (ChatGPT) a factual question, it gave you a wrong answer. I thought it was going to be so unimpressive that people would say, ‘Why are you doing this? This is so boring!’”.
But with hindsight, surprise at progress seems a common characteristic of all modern-day AI development. I remember being at Google when AI (or “machine learning” and “machine intelligence” as it was then termed) product experiments began. An early inkling of its potential was when after reviewing YouTube videos it learnt to discover cats. Soon after, AI began fuelling extraordinary leaps in quality for Google Translate. But the big surprise was when it got plugged in as part of the Google Search algorithm and within a few months grew unexpectedly to be the 3rd most important signal in determining search results. Modern AI is filled with such stories of how AI systems have delivered boosts in capabilities on a scale unforeseen by their developers.
» The pace of AI advance appears unstoppable
The AI race is real — not just at a company level, but also geopolitically. To quote from a recent Foreign Policy article:
“Whether for its repressive capabilities, economic potential, or military advantage, AI supremacy will be a strategic objective of every government with the resources to compete. The least imaginative strategies will pump money into homegrown AI champions or attempt to build and control supercomputers and algorithms. More nuanced strategies will foster specific competitive advantages… The vast majority of countries have neither the money nor the technological know-how to compete for AI leadership. Their access to frontier AI will instead be determined by their relationships with a handful of already rich and powerful corporations and states… This is not to say that only the richest will benefit from the AI revolution. Like the Internet and smartphones, AI will proliferate without respect for borders, as will the productivity gains it unleashes. And like energy and green technology, AI will benefit many countries that do not control it, including those that contribute to producing AI inputs such as semiconductors”.
Having advanced AI systems that are able to plan and strategise seems so useful that it is unrealistic to imagine that they won’t get built by someone, once the technical prowess is there. Perhaps policy guardrails or company upheavals (*cough* OpenAI *cough*) could slow the rollout pace by a few years (e.g., by restricting dissemination of the most cutting edge ‘foundation models’), but overall it feels unrealistic to expect AI’s development to slow unless technical limits are hit.
There are, as yet, no signs of this happening. Some have suggested that AI could run out of training data, but this seems unlikely given that ‘synthetic data’ (that is, data generated by AI models) is already being used and is not subject to the same constraints as human-generated data. Currently there is a shortage of human talent but this will change, not least as AI ‘copilots’ get ever more effective at training and supporting developers. Today’s shortage of semiconductors — an integral component of the GPU hardware used in training AI models — will presumably be addressed over time as chip manufacturing ramps up. (Indeed some chip manufacturers are already warning of a future glut, although constraints remain tight at the highest-tech end due to patents). Similarly, concerns about the cost of energy used in training AI models are driving efforts to develop less energy-intensive approaches.
Of course, just because a technology gets developed does not mean that it will be immediately embraced by society. Sometimes it’s too costly or in too unwieldy a form factor (think early mobile phones); sometimes it’s simply down to fear (think GMO foods). When it comes to generative AI, however, we seem far past this threshold (evidence: over 100 million ChatGPT users per week) with no sign of demand slowing. As one commentator put it
“ChatGPT is one of those rare moments in technology where you see a glimmer of how everything is going to be different going forward”.
» Modern-day AI is so complex that no one fully understands how it works
One of the most shocking things about today’s machine-learning based AI systems is that even its developers don’t know for certain how they work. This isn’t like the Expert Systems kind of AI from the 1980s, where people wrote lots of rules which functioned as signposts for the algorithm to follow. Modern-day AI works by throwing in a big pile of data, setting up a neural network, and letting it teach itself by using the data as examples. There are different training regimes for AI (in the form of algorithms), just like there are different educational styles for kids, but ultimately it’s experimentation and still an art as much as a science to get to something that works.

While AI is just mathematics at heart, it’s so complicated on a scale that in practice makes full understanding beyond the realms of human comprehension. There are techniques that with enough effort, expertise and time can yield a glimpse of key variables that affected an output, enough to support an educated guess at how a particular AI system might work. But this is far from the kind of detailed explanation that would support making reliable predictions of how an AI system will react to significantly different inputs. Nor is such depth of analysis viable to do on a mass scale, especially when systems are getting more complex all the time. Despite ongoing efforts of researchers, explaining how AI works remains a hugely challenging and far-from-solved technical problem.
2. Reasons why some people fear that AI could be catastrophic for human society
Today we have very powerful AI models, getting better all the time in ways we cannot predict or fully understand. We aren’t sure what their capabilities are now, let alone what they will be soon, and we have extremely limited visibility over who is using AI models and for what purposes, other than to see it’s spreading like a grassfire. What could possibly go wrong?
Once a fringe topic, worries about the long-term safety of AI have now spread across expert circles in the form of semi-joking conversational ice-breakers about p(doom), and increasingly public battles between tribes of AI doomers vs accelerationists.
Initially, concerns focused on the risk of superintelligent AI, as brought to the fore by Nick Bostrom’s 2014 book “Superintelligence: Paths, Dangers, Strategies”. Like it sounds, this is an AI that is super smart, exceeding even the performance of human experts — except that it is superintelligent across every topic (aka it’s an AGI = artificial general intelligence, to be precise). A flavour of this worry was nicely summed up recently in The Independent:
It is already difficult to understand what is going on inside the ‘mind’ of AI tools currently available, but once superintelligence is achieved, even its actions may become incomprehensible. It could make discoveries that we would be incapable of understanding, or take decisions that make no sense to us. The biological and evolutionary limitations of brains made of organic matter mean we may need some form of brain-computer interface in order to keep up.
Being unable to compete with AI in this new technological era, Professor Bostrom warns, could see humanity replaced as the dominant lifeform on Earth. The superintelligence may then see us as superfluous to its own goals. If this happens, and some form of AI has figured out how to hijack all the utilities and technology we rely upon — or even the nuclear weapons we possess — then it would not take long for AI to wipe us off the face of the planet.
A more benign, but similarly bleak, scenario is that the gulf in intelligence between us and the AI will mean it views us in the same way we view animals. In a 2015 conversation between Mr Musk and scientist Neil deGrasse Tyson, they theorised that AI will treat us like a pet labrador. “They’ll domesticate us,” Professor Tyson said. “They’ll keep the docile humans and get rid of the violent ones.”
But even if an AGI never reaches the level of superintelligence, some people still worry that it could be catastrophic. A recent paper “An overview of AI catastrophic risks” provides a good rundown on why, and this blog post has some more easily digestible scary vignettes. But broadly, the risks include:
Powerful AI tools being used in ways that increase the risk of other dangers — For example, bad actors could unleash bioterrorism using AI-engineered viruses, or use AI to help hack into critical infrastructure (e.g., taking control of nuclear plants). Of course the flipside is that the same AI tools can help in countering such threats. But even among those who have good intent, the more that people are under pressure to launch fast (such as to stay ahead of the competition), the greater the risk of unintended consequences and accidents.
Humans losing control over AI systems, and not being able to regain it — Such a risk arises if AI gets so capable at complex tasks like strategising and manipulating that it could — if it had sufficient agency and motivation — construct and execute a plan to seize power, outwitting any humans who tried to stop it. Some people refer to this as a power-seeking AI (there’s an excellent paper here that looks in detail at the likelihood of this situation arising: the author thinks it is >10%).
Misalignment between human values and an AI system’s goals — Even if developers are able to articulate the desired values to embed in an AI system (a far from straightforward feat), we don’t yet know how to do so in ways that are verifiably reliable. There are interesting attempts being made, for example Anthropic’s “constitutional AI”, but embedding values remains an unsolved technical problem. There is also the related challenge of how to spot any misalignment before it occurs with real-world consequences. Testing can only go so far, especially if the AI in question is capable of strategising and opts to “hide” its true nature. (Fun fact: this notion that an AI’s true nature may be unknowable is the core of the ‘shoggath’ meme — an example of dark geek humour). Unfortunately such behaviour can’t be just dismissed as a theoretical concern, as shown by the recent demonstration of a GPT4-based model lying about insider trading.
3. Roundup of what’s being done to address AI safety risks - by industry and by government
The first challenge — now largely overcome — was simply to raise awareness that there are credible broader AI safety risks worthy of consideration (in addition to the already well-known ethical concerns of AI fairness, explainability, accountability). The next bigger challenge is to find practical ways to reduce the risks, including better security (e.g., to protect against hackers seeking to tamper with models or steal key data) and safer deployment (e.g., reducing the risk of accidents, blocking mis-use by bad actors).
Right now, it feels like we are in ‘fixing the engine while the plane is flying’ mode when it comes to tackling AI safety risks. But there are reasons for hope, not least that policy makers have now got religion about AI safety, with a number of government-led initiatives taking shape globally (and quite swiftly relative to the usual glacial pace of such activity!) which has helped to focus minds and catalyse sharing of best practices in industry.
» What industry is doing
Until recently, with the notable vocal exceptions of Open AI and Anthropic (and more quietly DeepMind), most in leading AI labs ignored or downplayed the risk of AI causing wider societal catastrophe. Nor was it the focus of internal ‘responsible AI’ divisions, which were (justifiably) oriented to addressing ethical harms of the here-and-now, such as concerns about unfair bias. As a result, industry is still figuring out what techniques and tools are most helpful in reducing safety-related misalignment and control risks — and at an even earlier stage in putting the processes and standards in place to operationalise them.
Fortunately, progress is now being made. For example, in May a survey of experts were in strong agreement about instituting a wide variety of safety practices. While concrete details were lacking (as in reality they’re still being ironed out), this is a promising directional foundation for the development of more formal standards and policies.

Then in October, the UK government strong-armed leading AI labs into publishing their safety policies in 9 explicit categories. This proved helpful as a forcing device to get labs to share best practices in a broadly comparable format, and I suspect may also have encouraged some behind-scenes scrambling. As the Machine Intelligence Research Institute (MIRI) put it in their comparison of policies, “none are close to adequate, but some are importantly better than others, and most of the organisations are doing better than sheer denial of the primary risks”. (As context, while this might seem bad at first glance, it is high praise from the organisation whose founder, earlier this year, wrote an editorial calling for governments to shut all AI research down and “be willing to destroy rogue datacentres by airstrike”!!).
Here are what to me were the most interesting elements of responses by category:
Responsible capability scaling
Anthropic’s AI Safety Levels (ASL) framework for addressing catastrophic risks, modelled after standards for handling of dangerous biological materials.
Open AI’s wider concept of a ‘risk informed development policy’ (as they see increasing risk as not necessarily tied to scale), which has since resulted in their preparedness framework.
Model evaluations and red teaming
Anthrophic’s proactive approach to red teaming and third party auditing, and sharing research and datasets to help wider industry.
OpenAI’s commitment to expert red-teaming.
DeepMind’s evaluation framework for extreme risks.
Model reporting and information sharing
Meta’s detailed documentation that accompanied the open-source release of their Llama2 model (although it does not include details of training data used — but I forgive them this as furore over copyright has sadly had a chilling effect on anyone publishing such information now).
Security controls including on model weights
Google’s Secure AI framework, which while perhaps a tad generic and ‘we will do’ oriented, is nonetheless a helpful signpost.
Anthropic’s secure model development framework, with a focus on two-party control and embrace of AI adaptations of software development standards.
Reporting structure for vulnerabilities
AI incident database established by Partnership on AI (backed by many of the leading AI labs).
Identifiers for AI-generated material
DeepMind’s SynthID beta tool that can be used to inject watermarks, as well as to help to detect imagery generated by their Imagen model (with potential to extend to other AI image generator models in future).
The Synthetic Media framework developed by Partnership on AI (backed by many leading AI labs).
Prioritising research on risks posed by AI
Open AI’s commitment to dedicate 20% of their compute resources to a newly formed ‘SuperAlignment’ team with the goal of solving the problem of alignment in superintelligent AI systems within 4 years. In mid-December this team published their first research paper, exploring whether a less-capable model (GPT2) could be used to supervise a more capable one (GPT4), as an analogy for humans supervising superintelligent AI.
Preventing and monitoring model misuse
The most interesting thing here was how few interesting examples there were to find! Most AI labs have stood up bug bounty schemes, which encourage others to report problems, but the only concrete proactive example I spotted was Microsoft’s mention of abuse monitoring for their Azure OpenAI tool, for which they store all prompts/generated content for up to 30 days (except for customers who have been pre-approved for turning abuse monitoring off). Perhaps such reticence by AI labs to monitor (or at least, to talk about their monitoring) is not surprising given concerns over user privacy?
Data input controls and audits
OpenAI’s measures to make it easy for website operators and image creators to block their material from being included in future model training datasets.
So far most attention has been on the activities of the biggest AI developers, which makes sense as today they possess and are creating the most powerful models. Ultimately however, as advanced models become available for wider use, anyone who deploys them needs to think about safety in all of its dimensions, especially in high risk settings. There is already guidance emerging for businesses beyond big tech on how to use AI responsibly, and we can expect more to come. For instance:
Non-profit RILabs have published Responsible AI commitments and protocols for startups and investors with the endorsement of the US Commerce Secretary, which includes (among other things) a requirement to assess risks relating to reliability and robustness, security and resilience, privacy, unfair bias and alignment and safety.
Guides to using AI responsibly in specific contexts are proliferating — for instance in legal settings (inside law firms; use by judges); in financial services; in education; in marketing, in retail, in human resources (hiring, monitoring staff)… the list is endless.
More generally, there are frameworks and guidance on managing business AI risks from management consultancies like McKinsey, BCG, Forrester, Deloitte.
I’ll probably return to the topic of how everyday businesses (beyond big tech) should manage AI risks in a future note. Until then, as a matter of basic hygiene, all businesses should start now to more formally assess, monitor and document the ways in which they are using AI, to make it easier to comply with any future rules or codes of conduct that emerge. This is not only responsible behaviour, it’s also better than the alternative of scrambling retroactively to gather such information (especially if those involved have since left the company!)
» What governments are doing
Typically, tech policy initiatives come late, once industry has already worked out best practices and road-tested benchmarks and standards. Regulation then becomes a way to package this guidance and inject additional ‘teeth’ to incentivise good behaviour where it is needed. What’s interesting to me about the AI safety sphere is that policy makers seem to be playing an unusually catalysing and collaborative role in spurring wider industry to engage with the issue.
It’s no exaggeration to say that the race to develop powerful general purpose AI has now spawned a parallel race among governments to make progress and lead in imposing measures to control it. In the last 3 months of 2023 alone we saw the following initiatives:
G7 Hiroshima AI Process: At the end of October, Guiding Principles for Organisations developing Advanced AI Systems were published, along with a reasonably detailed voluntary code of conduct for developers. While not legally binding, they provide a framework for self-regulation, as well as for governments working on regulatory proposals. Although still general by nature, they do provide some concrete guidance by referring to the need for ‘red teaming’, security controls, incident disclosure, publishing transparency reports, and enabling traceability of development (such as data used, training processes, decisions made).
US Executive Order on Safe, Secure and Trustworthy AI: On 30th October in a surprise move President Biden issued binding principles and priorities for Federal agencies in the US using AI systems, which by their nature will have spillover impact on the private sector as well. In particular, it requires US developers of dual use foundation models whose training used more than a certain level of compute to report details to the US government (including cybersecurity protections in training, who has access to key ‘secret sauce’ information, and results of red teaming safety tests). US companies who have large-scale computing clusters also have reporting obligations to the government, including their location, size and whenever a ‘foreign person’ seeks to use them for training large AI models.
UK AI Safety Summit: On 1–2 November, the UK hosted a high level international summit to discuss AI safety, focusing solely on the risks of ‘frontier AI’ (aka highly advanced foundation models). This resulted in the Bletchley Declaration — signed by 28 countries, including remarkably both the US and China — making a public symbolic commitment to cooperate on AI safety. Followup summits are planned by South Korea (in virtual form in early 2024) and in France (in person in November 2024) — at which hopefully more concrete actions will be tabled. Relatedly, there was promising news in mid November when the US announced they would hold AI risk and safety talks with China.
Establishment of US and UK government-backed AI Safety Institutes: At the start of November it was announced that the United States AI Safety Institute (US AISI) would be formed inside NIST (US’s National Institute of Standards and Technology) to develop technical guidance and enable information-sharing and research collaboration with peer institutions. In parallel, the UK’s AI Safety Institute was announced as an evolution of the UK’s Frontier AI taskforce. It will test new types of frontier AI before and after they are released. All companies participating at the UK Safety Summit have agreed to provide access to their models for such testing (including Amazon Web Services, Anthropic, Google, Google DeepMind, Inflection AI, Meta, Microsoft, Mistral AI and Open AI).
European Union’s AI Act: In mid-December after some highwire posturing, there was finally agreement on the broad outlines of the EU’s flagship AI regulation. One of the most contentious areas was the treatment of general purpose foundation models. In the end,the compromise was for all such models to be required to provide some basic transparency (e.g., technical documentation, summary of training data used), and for only those models which consume more than a certain (tbd but high) threshold of computational resources in training to also conduct adversarial testing, formal risk assessments, as well as report on serious incidents and more. The requirements on foundation models are expected to come into force in 2025.
In addition to these recent high-profile diplomatic and regulatory initiatives, there’s also been a body of longer-term work in government-backed technical standards organisations to publish concrete guidance on how to use AI safely and securely. To namecheck but a few:
In the UK the CDEI, Turing Institute and ICO have combined produced numerous practical guides on using AI responsibly, such as on AI Assurance and explaining decisions made with AI.
In the US, the National Institute for Standards and Technology (NIST) is doing god’s own work in collaborating with industry and academia to produce standards for cybersecurity, AI risk management and (in progress) for AI testing. (While other international standards bodies such as ISO and IEEE have also long been working on AI standards, their wheels turn v..e..r..y slowly, whereas NIST has proven itself to be remarkably nimble, as well as willing to share its guidance free-of-charge).
In China, the National Information Security Standardization Technical Committee (TC260) has issued standards for labelling AI-generated content, and are currently drafting standards for security of generative AI.
Overall, while it’s unclear where all this will eventually lead, it does seem to have transcended being just a talking shop. It’s thus likely to end with some form of international oversight for AI — but whether that takes the the shape of a formal body (e.g., like CERN or NATO or the international atomic energy agency) to oversee AI development; or happens more organically via international treaties — it’s too soon to tell. What matters more for businesses is that AI is now firmly on the radar of policymakers — and thus it’s worthwhile to keep an eye on the direction of travel of such discussions to have a sense of how (if at all) it may affect your industry sector in future.
4. Personal perspective: am I worried?
» I’m much more worried about AI today than I was two years ago, mostly because experts that I trust are now worried.
A decade ago concerns about losing control of AI were the province of philosophers and the occasional pop scientist:
“With artificial intelligence we are summoning the demon” — Elon Musk
But, given AI’s limited capabilities at the time, I dismissed such quotes as hyperbolic. I presumed we wouldn’t face existential AI control problems for many decades (if ever), at which point we’d also have developed the tools to handle it.
But there’s been a big shift in the past year, after the dramatic leaps in performance of GPT4 and its ilk. Now even some of the expert researchers responsible for modern AI breakthroughs are ringing alarm bells:
“We can’t be in denial, we have to be real. We need to think, how do we make it not as awful for humanity as it might be?” — Geoffrey Hinton
“It’s going to be monumental, earth-shattering. There will be a before and an after.” — Ilya Sutskever.
I’m not alone in being shaken up by this shift in expert perspectives — it’s arguably why policy makers are also now taking safety risks seriously. About the only reassurance is that other experts of similar eminence remain dismissive of fears:
We’ve been designing guardrails for humans for millennia. That’s called laws. The difference is that with AI systems, we can hardwire those laws into their way of acting. We can’t do this with humans. So I think it’s gonna be much, much easier to make AI systems safe than it is to make humans safe” — Yann LeCun
Unfortunately, the fallout from OpenAI’s leadership drama has made things worse. As Casey Newton summed up, we now find ourselves in a world where
“AI safety folks have been made to look like laughingstocks, tech giants are building superintelligence with a profit motive, and social media flattens and polarises the debate into warring fandoms. OpenAI’s board got almost everything wrong, but they were right to worry about the terms on which we build the future, and I suspect it will now be a long time before anyone else in this industry attempts anything other than the path of least resistance”.
» But here’s why I remain cautiously optimistic about AI’s impact
Underpinning my perspective on how much to worry are some specific beliefs. Maybe I’ll change my mind on some of them as the technology — and society’s embrace of it — evolves, but this is why, currently, I’m still optimistic about AI:
(1) I believe humankind is adaptable and resourceful.
As highly capable AI becomes integrated throughout society the pattern of people’s daily lives is likely to change profoundly (just as the arrival of cheap artificial light transformed working patterns and how people sleep) — but it won’t happen overnight, and the choices that individuals and societies at large make in how to engage with AI will shape its ultimate impact. Yes there will be winners and losers; but since change is inevitable I prefer to adopt a ‘glass half full’ mindset. As Jaron Lanier put it:
“Anything engineered — cars, bridges, buildings — can cause harm to people, and yet we have built a civilization on engineering. It’s by increasing and broadening human awareness, responsibility, and participation that we can make automation safe”.
(2) I genuinely believe advanced AI is a tool that may present our best (and maybe only) shot at tackling major existential threats such as climate change and antibacterial resistance.
Thus to me, the opportunity costs and risks of NOT having advanced AI are a counterbalance to the risks of having it, so long as we manage it sensibly. This includes concerns about the impact on jobs and inequity, which I believe are ultimately within society’s control to address (albeit I fear a bumpy transition if changes occur faster than our institutions adapt).
(3) Safety problems like misalignment are going to be undeniably tough to crack.
But until recently not many people were even working on it, so there’s reason for hope.
It is helpful too that there is a long-term commercial incentive to improve alignment, not just a safety one. After all, misalignment is ultimately a performance quality issue, as few will want to buy something they can’t rely on to behave as intended in a production setting.
(4) Explainable AI would be great, but isn’t essential for AI to be useful.
Aspiring to fully understand how AI works is a hugely worthwhile endeavour, since even a partial explanation is reassuring, but ultimately I fear explainability is a Sisyphean task. Even if researchers make a dent on mechanistic interpretability, it will get ever-harder as AI models increase in complexity.
I’m OK with this though, so long as there are appropriate guardrails when AI is being used in decision-making (e.g., processes for accountability and a degree of human oversight). While putting faith in decisions that I can’t fully understand is not comfortable, it doesn’t scare me because we don’t truly know the human reasoning behind decisions either. (Sure someone can tell you their rationale, but that doesn’t mean it is a truthful or complete answer as people have unconscious biases and selective memory, and there is no objective way to test as we still have little clue how even a human brain works!).
(5) I’m more worried about openness than about concentration of power.
People talk about it being a bad thing for the most powerful AI models to be controlled by just a handful of tech companies, but honestly I’d prefer that since at least then you could get everyone around a table to agree on guardrails. But it’s too late now — the moment the first foundation models were let loose in the world via open sourcing and leaks, was, for me, the point of no return as now there is no way to tell for sure who is even in the AI race. While today the cost of computation provides a partial brake on proliferation, there’s still plenty of opportunity for improvement (and potential havoc) in fine-tuning or daisy chaining existing older models.
I get that there are advantages to openness from an economic competition perspective, such as in giving smaller nations a leg up in tailoring systems that are a better fit for their cultures and needs. But sadly I don’t buy the argument that open sourcing de facto makes AI safer, since even if there were enough experts to pick over model details and spot problems, there’s no guarantee they’d be found and fixed before they got exploited.
(6) I’m more relaxed about China and AI than most people.
It feels a bit heretical to say given China’s human rights violations, authoritarianism, and fundamentally different attitudes to privacy — but China was ahead of the US and Europe in implementing regulations for AI (albeit in line with Chinese cultural values rather than the West’s). This report gives a good overview of the situation in China in relation to AI safety, and suggests China is seemingly being just as cautious about AI development as the US and Europe. This isn’t to say I’m not worried about what might happen to the West economically if China or India or UAE or (insert non-Western nation) leapfrogged ahead in AGI capabilities, but to me that’s a separate consideration to safety, and so beyond the scope of this essay.
(7) Some safety problems get mis-attributed to AI.
To be clear, I’m not suggesting there aren’t any new or heightened safety risks presented by advanced AI. Just that we should be clear-eyed about existing risk levels. For example, while AI may make it much easier to learn how to design a biological weapon, the same information is already findable online by those motivated to dig. The scarier issue is the lack of security checks in ordering DNA materials needed to act in this knowledge — which is not an AI-related problem. Similarly, you don’t need advanced AI to run a successful misinformation campaign, as past political campaigns demonstrate. Paradoxically it’s possible that growing awareness of deep fakes and hallucinations might lead people to be savvier about judging the veracity of information — perhaps even ushering in a new heyday for traditional media in the guise of it being a trusted source. It’s too soon to tell, but I don’t see it as necessarily all doom-and-gloom.
(8) What matters most is being able to detect problems early enough
and having the resources to intervene.
Detecting problems, and the impact of any attempted remedy, is much more of a challenge with AI than other ‘dumb’ technology, since advanced AI may be capable of deception. Upfront testing is helpful but far from sufficient — AI systems need expert ongoing monitoring, and I fear that’s an aspect that has not yet received the investment or attention it deserves (by companies and governments alike). Regulation is not enough; we also need expert groups who can intervene in a crisis, akin to tackling cybersecurity threats. My biggest safety concern about the AI race is not with the pace of advancement, but the lack of marshals monitoring and the absence of expert emergency medics poised for rapid response. I’m hopeful that the recently announced AI Safety Institutes are a starting point for this but let’s see.
If you’ve read all the way through, thank you for bearing with me!
I hope this has been a useful and thought-provoking jaunt through the key aspects of the AI safety debate. It’s certainly been a useful exercise for me to write, as a forcing device to articulate and fully think through my own position. AI is a hugely promising technology, but it’s undeniable that it also comes with some risk of peril. The choices we make now, as a society, in the manner we progress and embrace AI matter hugely.
If you have any thoughts on this, or different perspectives to share, please do comment below :)
This is a fantastic overview of AI Safety that is both accessible and super informative. I really appreciated the balanced perspective.